Using DocDigitizer PowerCapture API
Using DocDigitizer PowerCapture API
DocDigitizer PowerCapture API - Main Services
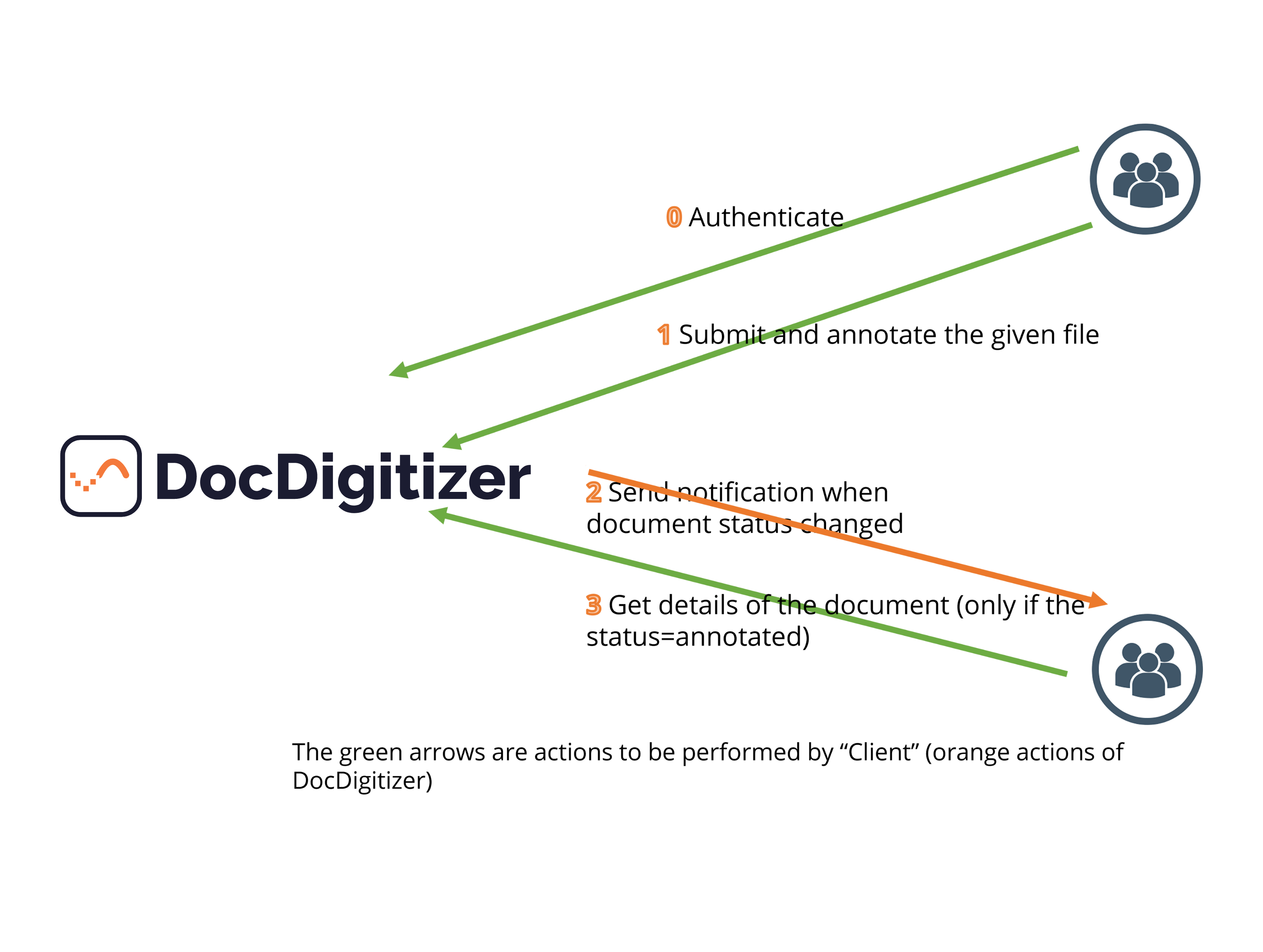
- Authorization : pass your API Key
- Authorization :
accessToken
Path Parameters: document_class: optional parameter (indicated the type of document being submitted
possible values: “financial-document”, "invoice", "pay-slip", "bank-statement", "citizen-id-card", ...
Body Parameters:documentClass: indicated the type of document being submitted
possible values: "invoice", "atm_receipt", "bank_statement", "payslips", "citizen_card_id_front,citizen_card_id_back", "citizen_card_id_front", "citizen_card_id_back", ...useHumanRevision: indicate if you want to use human revision (data validation/curator process)
possible values (Boolean). true | falseisSync: indicate that you want to wait for the response 8activy wait). Pass true only if "useHumanRevision" is false.
possible values (Boolean). true | falsefiles: file to submit to extract data
- Authorization :
accessToken
Path params: docid: document id (receive in the Header response of "Submit and annotate the given file")
Call this service when receiving “Notification” withstatus=reviewed(passing the correspondingdocument_id)
If you don’t have callback define, to check if the process of corresponding docid is finished, check the field statusText.
The statusText can have several values but the ones to check on the client side are:
- ANNOTATED : process finished. Data extracted is available
- REJECTED : process finished & document rejected (e.g. illegible data, invalid document, ...)
- ERROR : process finished in error. Reasons can be several but normally because the document type is invalid or cannot be read.
Updated 10 months ago