Using DocDigitizer PowerCapture API
Using DocDigitizer PowerCapture API
DocDigitizer PowerCapture API - Main Services
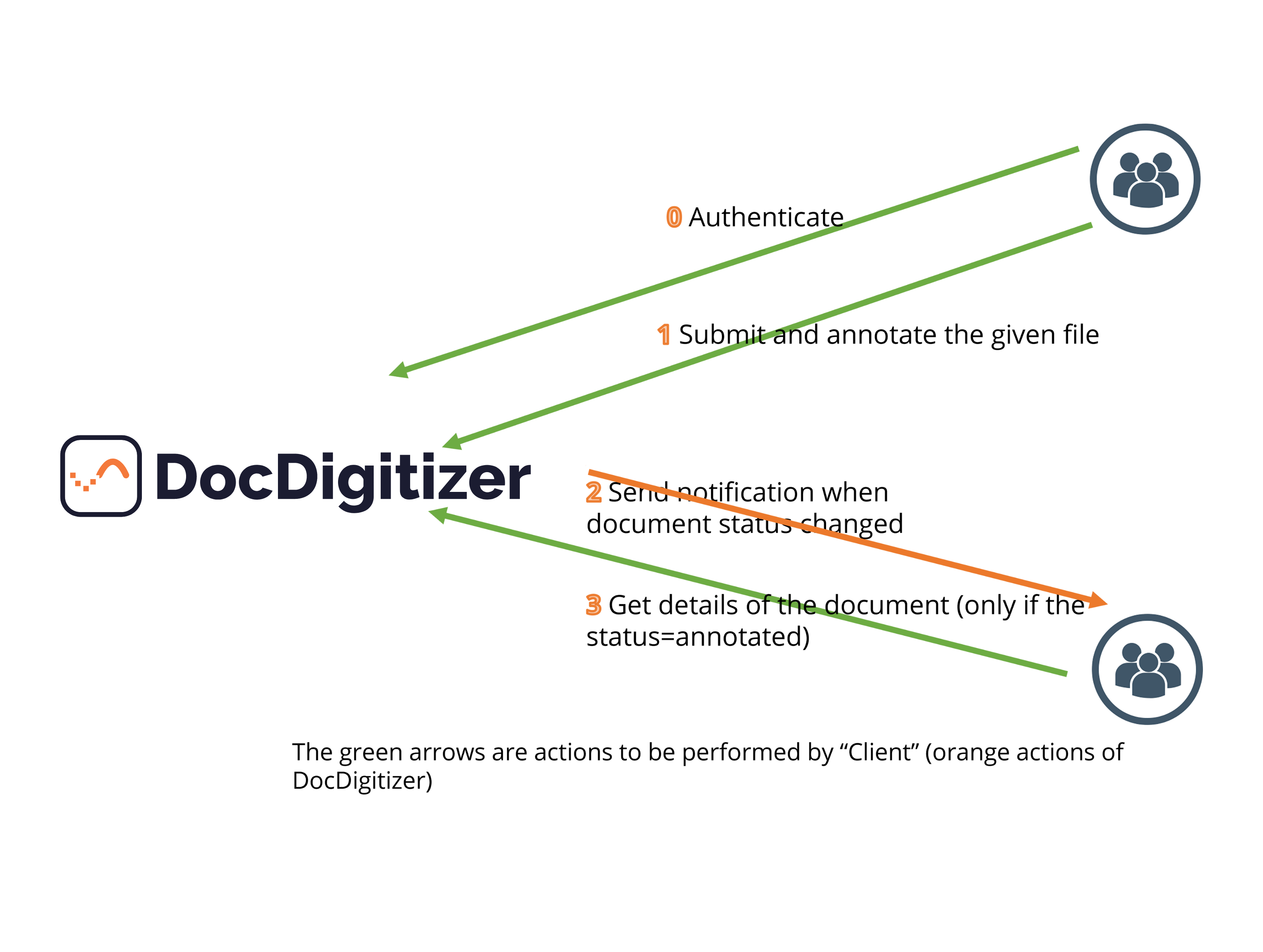
Authentication
Purpose: authenticate the client, If success, you will receive 2 tokens: 'accessToken' and 'refreshToken'
You'll need to authenticate only once for as long as your token hasn't expired.
You must use the 'accessToken' against the rest of the endpoints.
Once it expires, you can either authenticate again or use the 'refreshToken' to issue a new pair of tokens.
Method: POST
Header Parameters:
- Authorization : pass your API Key
Submit and annotate the given file
Purpose: submit a file to be extracted. In the response you get the value of document_id that identify the file submitted and that you can use to get their data.
Method: POST
Header Parameters:
- Authorization : Bearer 'accessToken'
Body Parameters:
-
document_class : optional parameter to inform us the class of document being submitted. Please check the list of all classification classes.
-
useHumanRevision : optional parameter to indicate if you want to use human revision (human-in-the-loop process).
Possible values are Boolean true (default) or false. Please check the table bellow. -
isSync : optional parameter to indicate whether the response should be synchronous or asynchronous.
Possible values are Boolean true or false (default). Please check the table bellow. -
files : mandatory parameter to inform the file(s) to submit and get their structured data
-
callbackUrl: optional parameter to inform the customer callback service endpoint, to be called when file is ready. You can give us a public endpoint that we'll call it by GET (or the method provided) when we finish the document processing.
We'll append a doc_id and status parameters to whichever query string you give us on this parameter. The status string could be one of ANNOTATED, REJECTED or ERROR. -
callback_method: optional parameter to inform the method used to call the callback service, one of GET (default) or POST
-
callback_headers: optional parameter to inform a dictionary of (key, value) strings to be passed back to your callback service by http header
Get details of the document
Purpose: Get data extracted from the document submitted
Method: GET
Header Parameters: -
Authorization : Bearer 'accessToken'
Path Parameters:
- docid : document id (received in the Header response of the "Submit and annotate the given file")
If you have defined your callback service, then you should call this service after receive a “Notification” with status=reviewed or READY (passing the corresponding document_id).
After all just make sure that you use the results when the field 'statusText' is READY (or ANNOTATED).
The 'statusText' can have several values:
- PROCESSING: document is in process
- READY: document is ready to be used by our customers (it's a final state)
- REJECTED: document was rejected and the reason is also provided (it's a final state)
- ERROR: document processing raises an error and their results are incomplete or unavailable (it's a final state)
- ANNOTATED : this is an obsolete state, but with the same meaning as the READY state
What are the use cases related with isSync vs useHumanRevision?
| isSync | useHumanRevision | What happens? |
|---|---|---|
| false | false | Extraction results will be available asynchronously by calling the Get details of the document API, and the document classification and extraction process will be made automatically (without human in the loop) |
| false | true | This is the default behavior. Extraction results will be available asynchronously by calling the Get details of the document API, and the document classification and extraction process will be made automatically and with human in the loop, assuring the best accuracy. |
| true | false | Extraction results will be available synchronously, and the document classification and extraction process will be made automatically (without human in the loop) |
| true | true | Extraction results will be available in two phases: 1) synchronously, where the results are given automatically without human revision; and 2) by calling the Get details of the document API after state changed to READY, where the document classification and extraction process were done with human in the loop |
Updated 10 months ago