Using DocDigitizer PowerCapture API
Using DocDigitizer PowerCapture API
DocDigitizer PowerCapture API - Main Services
The extraction process is asynchronous and by default, have “Human Validation”.
For this reason, the data extracted will not be immediately available, having SLA in accordance with contract established (for the Trial/Demo accounts, SLA by default is 30mins)
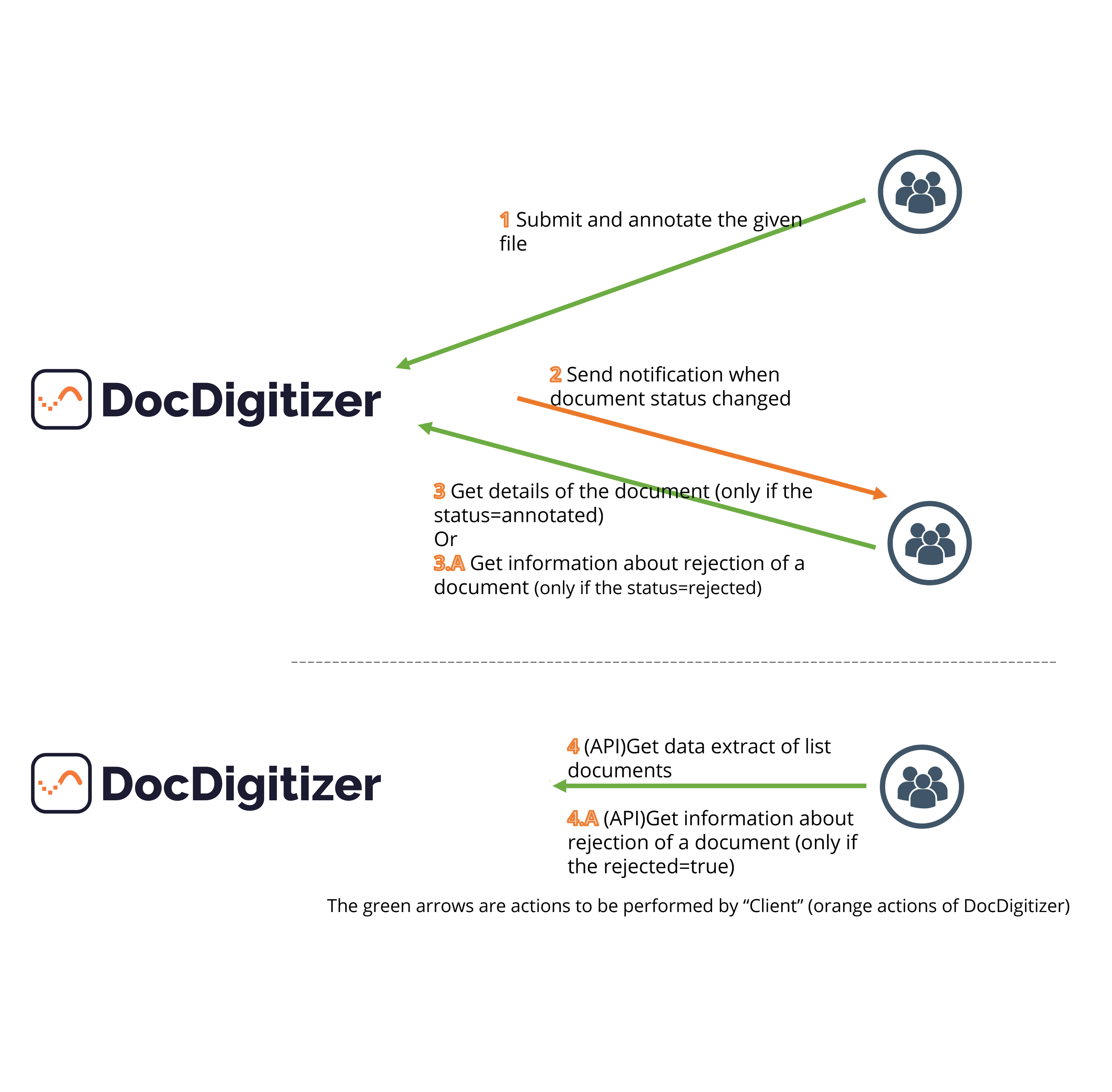
I have an API KEY, where should I use it?
HTTP Headers & Authorization
For your request to be authorized you need an API_KEY.
This API Key have to go in each request, key field Authorization
Also key field Content-Type = "multipart/form-data" is needed only for the "Submit document," because in this service you are sending files (encode the data that forms the body of the request).
headers = {
'Authorization': 'API_KEY ' + APIKEY,
'Content-Type': 'multipart/form-data'
}Example in Postman:
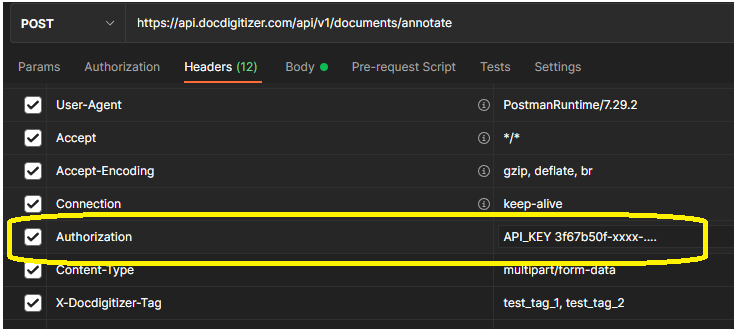
How can I send you my document to get its data extracted?
Purpose: submit a file to be processed. In the response you can obtain the corresponding document ID. This document ID is our key to identify the file submitted and you will need it for all API calls that gives you information about the file, see below how to do it.
Method: POST
Path Parameters:
- document_class : optional parameter, you can inform us the class of document being submitted, if you know it in advance and if it's available in your license. You can check our document class list here
Body Parameters:
- files : file to submit to extract data
- callback_url : optional parameter, should be the url of your API for you to be notified by Callback service (status notification)
- callback_method : optional parameter, parameter related with callback service to specify which method shall we use to call the service, only GET or POST is accepted. If this parameter is omitted we call with GET.
- callback_headers : optional parameter, parameter related with callback service to specify HTTP headers to pass when we call the callback service. This is a dictionary of key/value pairs of strings, like - callback_headers[<your_key>] = <your_value>. Example: callback_headers[Authorization] = API_KEY 7017f86c-6ea3-xxxx-xxxx-...
When sending the request, in case of Accepted (Status=202), you will receive a response similar to the following:
{
"detail": "Accepted",
"status": 202,
"task": {
"created": "2021-11-02T12:14:26.564283",
"id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"links": {
"self": "/api/v1/tasks/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"collection": "/api/v1/tasks"
},
"status": "PENDING"
}
}Example in Postman, in this case we also define a callback url to be called by POST with Basic Authentication defined for user 'demo' and password 'p@55w0rd' to be sending in Authorization header:
Now, how to get the document ID?
To get the ID of the document submitted to the DocDigitizer platform, you need to check the Header of the response.
Go to the Header response and check KEY X-Document-Location
The document ID value is the UUID that you find at the end of the URL
"X-Document-Location": "http://api.docdigitizer.com/api/v1/documents/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"How can I get the data that you extracted from my document?
Purpose: Get data extracted from a given document
Method: GET
Path params:
- document_id : document id (received in the Header response of "Submit a file")
If you informed us your callback API while submitting the file, call this service when receiving “Notification” with status=annotated (passing the corresponding document_id)
To check if the process of corresponding document_id is finished, check the field reviewed=true in the response.
And when I received rejected=true?
rejected=true?Purpose: Get information about rejection of a given document
Method: GET
Path params:
- document_id : document id (received in the Header response of "Submit a file")
And when I need to search for my submitted documents or get a list of them?
Purpose: Get a list of documents along with its extracted data
Method: GET
Parameters:
Request (Best practices)
Check pagination logic describe here
- Use default value for documents retrieve (
maxRetrieve) - If you only what the reviewed documents (excluding the rejected), pass the parameter “reviewed” a “only“
- Use of parameter
reviewed_after(returned documents reviewed after the given date) - Save the value of
review_dateof the first document receive, to be use on the next request (except in the case of requesting the next page, where the query parameters value used in the original order must be kept, exceptcursorId) - Pass the parameter
assets=1, if you want to include in the response the endpoint to the original document. Otherwise Pass the parameterassets=0
* This link (document) have a short lifetime (around 72 hours)
Response - In the response, check the field
rejected, that if it has the valuetruethis means that document was rejected.- In this cases you should call View document's rejection. to obtain information about the rejection
This service can also be used to check if there is new information
- Call the service with the same parameters/values to be used on the
GET, but instead use the methodHEAD- The
HEADmethod is identical toGETexcept that the server don´t return the message-body in the response
- The
To obtain detail information about DocDigitizer PowerCapture API, please consult API Reference v1.0
Updated 10 months ago